オブジェクト指向を知っている人々に、「関数型もオブジェクト指向と大差ないよ、大丈夫だよ」とお誘いする記事は大いに存在意義があると思います。
上記の記事は、そういう目的を持って書かれたのでしょう。その内容(目次)は次のようです(僕のこの記事の目次じゃないよ)。
- 対象読者
- なぜこの記事を書こうと思ったのか?
- なぜ関数型プログラミングはわかりにくいのか?
- オブジェクト指向の負の遺産を捨てよう
- 関数型プログラミングの概要
- 「阿吽の呼吸」とも言うべき使いやすさの拡張
- 型にまつわる考察
- まとめ
最初のほうを読むと、言ってることはまっとうで好感を持てます。が、「5. 関数型プログラミングの概要」の節あたりから雲行きが怪しくなって、ちょっと何言ってるかわかんない((c)サンドウィッチマン)。
檜山のこの記事の内容:
- 真面目なポエム
- モナドっておいしいの?
- オブジェクトは仮想機械
- そもそも関数とは何?
- 制御構造不要なら楽ちん!
- それで結局、関数型プログラミングはオブジェクト指向の後継なの?
真面目なポエム
「んんんーー??」と思って「はてなブックマーク」コメントをチェックしたら、id:kmizushimaさんが「ポ、ポエムだー!!」と叫んでいました。
僕の言葉で言えば、retemoさんによる当該Qiita記事は「具体的じゃない」ものです。僕の「具体的/抽象的」の用法は、たぶん標準的日本語とズレていて、「具体的じゃない」は、「掴み所がない」とか「あやふや過ぎる」といった意味で使います(抽象的かどうかとは無関係)。詳細は次の記事:
retemoさん記事は、何か言いたいことがあるのは確かだし、それがひどくトンチンカンだとも思いません。具体性に欠けるので、“ちょっと何言ってるかわかんない”(kmizushimaさんの言う“ポエム”)になっているのでしょう。“何言ってるかわかんない”けど、「真面目さ」が感じられて、僕の好感はさほど損なわれませんでした。
意味不明な記述を僕なりに解釈・注釈し(それが無理な所もあります)、多少の補足をしてみます。解釈に推測が入るので、「たぶん…らしい/でしょう」の表現が多用されます。歯切れ悪いけど、推測だからね。
このテの話題は、当ブログ「キマイラ飼育記」で10年以上に渡って扱ってきたものですから、掘り返せば、たいていのことが過去記事にあります。再度説明する代わりに適宜リンクを挿入します。大部分の説明を参照にしても、それなりに長い記事になってしまいました。
混乱が起きないように注意しておくと、引用はすべてretemoさん記事からです。自分の記事は引用してません。参照のみです。それでも参照と引用が混乱しそうなところには横線を入れて区切ってます。
モナドっておいしいの?
《関数型プログラミングはオブジェクト指向の正当な後継である - Qiita 3.なぜ関数型プログラミングはわかりにくいのか?》
関数だけをとっても理解しづらいのですが、さらに高度な概念で構成されるモナドについては聞けば聞くほど混乱が増すばかりです。
この問題をなんとか改善しようと言葉を選んでいるケースもあるのですが、それはそれで「詩的」というか「俳句的」というか、”ふんわり"し過ぎな傾向があります。
同感です。“ふんわり”し過ぎを避けて、でも厳密過ぎもしないレベルの説明を書いたことがあります(10年以上前)。
同様な趣旨、具体例で(9年以上前):
圏論に慣れたきたら、「モナドとは自己関手圏のモノイドなり」と理解するのが良いでしょう。
「圏論? 全然わからん!」なら、シリトリから始めましょう(これも10年たった)。
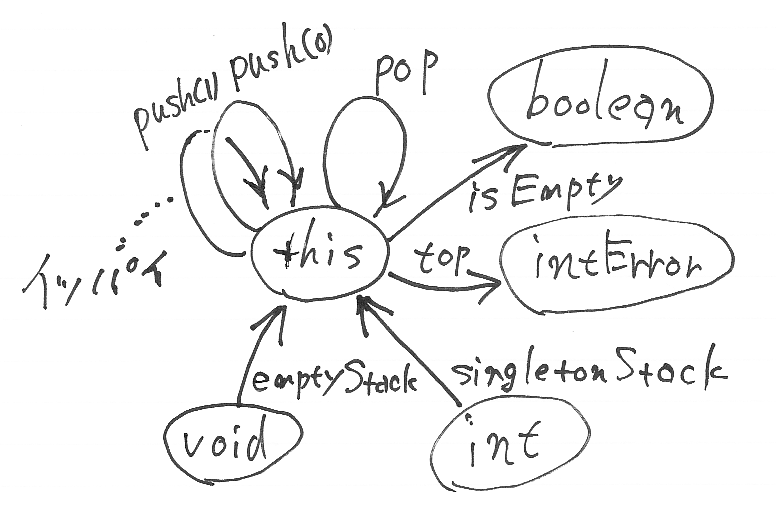
オブジェクトは仮想機械
《関数型プログラミングはオブジェクト指向の正当な後継である - Qiita 4.オブジェクト指向の負の遺産を捨てよう》
オブジェクト指向のオブジェクトは[...snip...]古き良きチューリングマシンから今日の仮想化技術までを含む「抽象的な概念」としてのコンピュータです。
オブジェクトを仮想機械とみなすのも共感・賛同します。
ここで言う仮想機械は、あくまで概念的なステートマシンです。
ステートマシンは「状態」と「遷移」、そして遷移を引き起こす「イベント」で構成されます。イベントにはトリガーやガード条件を含まれていて、「制御」と言いなおすことができます。同様に状態と遷移も「変数」及び「演算」と言い換えることができます。この「変数、演算、制御」がプログラミング言語や抽象的コンピュータの3大要素です。
僕は「言い換え」はしないほうがいいと思いますが、まー、ここは好みの問題としましょう(突っ込まない)。「イベント」はラベル付き状態遷移系(labeled transition system)のラベル、オートマトンの入力記号のようなものだろう、と、たぶん。「制御」が何を意味するか? ハッキリとは理解できませんでした。ガード条件を引き合いに出しているので、状態点に対する述語(状態空間上で定義された真偽値関数)をp、遷移を引き起こす関数(状態空間上の自己写像)をaとして、
- if (p(x)) then a(x)
のような条件付き実行を「制御」と呼んでいるのでしょう。
実際、クリーネ代数の演算(順次結合、非決定性選択、非決定性繰り返し)に、if (p) then a というスタイルの「制御」(ガード付きの実行)を入れると、whileプログラムをシミュレートできます。
よって、「順次結合、非決定性選択、非決定性繰り返し」を暗黙に前提した上で、仮想マシンとしてのオブジェクトが「変数(状態)」「演算(遷移)」「制御(ガード条件)」から構成される、とするのは、悪くない定式化だと思います。
これら4つがオブジェクト指向を代表する技術トピックでしょう。[...sinp...]この4大トピックが1つ目の「定性的な物差し」です。
「これら4つ」とは、次のことらしいです。
- 継承と多態性の技術
- 独立したオブジェクト間をメッセージングでつなぐ技術
- 問題領域の区割りと仮想機械の区割りを関連付ける技術
- 仮想機械間の役割分担
僕は、原則だのトピックが4つだ5つだ、という数え上げには興味がないので、どうでもいいですが、「定性的な物差し」ということですから留意しておきましょう。「物差し」と言っているのは、これら4項目において、オブジェクト指向と関数型を比較しようじゃないか、という意図(らしい)です。
そもそも関数とは何?
《関数型プログラミングはオブジェクト指向の正当な後継である - Qiita 5. 関数型プログラミングの概要》
関数型プログラミングの関数の特徴を簡潔に理解しようとすると、注目すべきは「参照透過性、関数合成、部分適用」の3つです。これらを順に見ていきましょう。
参照透過性は「入力が同じなら必ず同じ答えを返す」と書いてあるので、関数の純粋性と同じ意味ですね。あいにく僕は、純粋があまり好きじゃないです。
好き嫌いの話なので、別にいいとしましょう。関数合成の話も簡単だからいいとしましょう。んで、部分適用の話:
「部分適用」というのは「複数の引数を受け取る関数」に対して部分的に引数を渡すと、関数からは「足りない分の引数を取る関数」が返ってくる機能(というか技術)です。つまりたくさんの引数を持つ関数を段階的に実行することができます。
これはいい説明だと思います。でも、この説明の前後がなんか変。
[部分適用は]名称から「関数合成」と関係してそうなことは想像ができると思います。
名称から言ったら「関数適用」と関係するでしょ。「たくさんの引数を持つ関数を段階的に実行する」のは合成(composition)を繰り返してるんじゃなくて、適用(application, evaluation)を繰り返してます。
部分適用の説明の後で、「他にも」として、カリー化や高階関数が紹介されてますが、部分適用が出来るのはカリー化された高階関数だからであって、別な機能じゃないです。もっとも、部分適用を構文的利便性と解釈するなら、それを実現しているメカニズムがカリー化/高階関数だとは言えるので、「縁の下の力持ち」という文言を考慮すれば、これもまーいいか。
制御構造不要なら楽ちん!
「5. 関数型プログラミングの概要」のサブセクション「モナドのない関数型なんて」になると、だいぶ解釈が苦しくなります。retemoさんはモナドの雰囲気を伝えたいらしいのですが、僕は理解できません。
モナドは多様だということで、次のような記述があります(太字強調は檜山)。
- IOモナドはインターフェース役であることが一目瞭然
- ArrayモナドやDictionaryモナドあるいはリスト・モナドが構造役であることも疑う余地はない
- モナドは合成関数を作ってサービス役にもなれる
- モナドの主な使い方は「保持役(状態役)に暗黙の制御構造を付与すること」になります
この「ナントカ役」に関する知識が僕はないので分からないのかも知れません。センテンスレベル/パラグラフレベルでは“ちょっと何言ってるかわかんない”のですが、全体として「明示的な制御構造が不要になるから便利!」と訴えているのは伝わります。
例えば、Optionalモナド(Maybeモナド)なら、次のような明示的if文が不要になる、ということでしょう。
if (isUndefined(x)) { // xの値が未定義のときの処理 } else { // xの値が存在するときの処理 }
それ[Optionalモナド]が本領を発揮するのは関数をOptionalチェーンで繋げる時です。
「Optionalチェーン」と言っているのは、Optionalモナドのクライスリ結合のことでしょう。条件分岐しながらの関数合成がスッキリするから便利だ、と。実際、そのとおりです。
Listモナドのmap関数であれば、List.map(f)(x) と書けば、次のforループを不要にしてくれます。
var y = []; for (var i = 0; i < x.length; i++) { y.push(f(x[i])); } return y;
制御構造要らん、あー、便利だ。と、たぶん、そんなことを言いたいのでしょう。
《関数型プログラミングはオブジェクト指向の正当な後継である - Qiita 6.「阿吽の呼吸」とも言うべき使いやすさの拡張》
「継承と多態性の技術」は、1つのメソッド名で型に応じた別個のメソッドを自動的に呼び分けることができます。つまりは型をパラメータとしたswitch文的な条件分岐が暗に含まれているわけです。
「継承と多態性」はswitch分岐(型case)を不要にしてくれた、モナドもif分岐やfor繰り返しを不要にしてくれる、どっちも制御構造を不要にするから似てるよね、という話だと思います。
分かりきった手続きについての言及を省略した、言い換えれば「阿吽の呼吸」とも言うべき、そのユーザーフレンドリーな「暗黙の制御構造」の応用範囲をモナドは広げてくれるわけです。実際、多態性とモナドの使用感はよく似ています。
確かに、抽象化により煩雑な記述が省略できる点で多態性とモナドは似てなくもないですが、くくりが大雑把過ぎるかな、とは思います。このくくりなら、オーバーロードも入れちゃってもいい気がします。
それで結局、関数型プログラミングはオブジェクト指向の後継なの?
疲れてきた。残りは急ぎ足。
残りの4つの節も、“ちょっと何言ってるかわかんない”表現が多いですが、特に難儀だったのは:
《関数型プログラミングはオブジェクト指向の正当な後継である - Qiita 7. 型にまつわる考察》
「構造を抽象化した型」は「ジェネリック(C++ではテンプレート、Haskellでは型コンストラクタ)」で、「扱いを抽象化した型」は「インターフェース(Swiftではプロトコル、Haskellでは型クラス)」であり、オブジェクト指向と関数型プログラミングのいずれにも存在しています。
「構造」と「扱い」という言葉が分からなくて、一見では意味不明なんです…
「ジェネリック」は型パラメータを具体化して型を返す、という意味らしいので、「構造を抽象化」するとは、具体型から型パラメータへの置き換え、かな、たぶん。「インターフェイス」が「扱いを抽象化」と言っているのは、具体的なメソッド群から実装を剥ぎとって名前だけにした、ってこと、かな、たぶん。
このへんは、ソート、指標、モデルといった概念で理解するのがいいと思いますよ。
できればインスティチューションで分析したいところ。割と圏論バッキバキだったりするんだけど:
Haskellでは型同士の継承をサポートしていませんが、型クラスから型インスタンスへの継承はできるため、それを利用した多態性の実現が可能です。
「型クラスから型インスタンス」は文字通りインスタンス化であって継承とは言わないでしょ。言ってもいいのかな? …… やっぱり、区別したほうがいいと思います。
型クラスの話題だとCoqになってしまうけど、多少は参考になるかも↓
さて、「オブジェクトは仮想機械」で挙げた「オブジェクト指向の4大技術トピック」に関しては、若干の説明の後で:
つまり実はオブジェクト指向の4大技術トピックは全て関数型プログラミングに継承されているわけです。
プログラミング言語AあるいはパラダイムAのメカニズムは、プログラミング言語BあるいはパラダイムBでシミュレートできる、逆のシミュレートもできる、という状況は多いです。そうなると、BがAの後継者とか進化形というよりは、A, Bお互いがメタ・ポジションを取りあう(実際は互角、割と不毛な)議論になるんじゃなかろうか。
[...snip...]どう見てもオブジェクト指向と関数型プログラミングは直系ではありませんが、[...snip...]
歴史的経緯や、言語設計者の意図の観点からは、「関数型プログラミングはオブジェクト指向の正当な後継である」と主張するには無理がありますよね。
こうしてみると表面上はかなり違って見えるオブジェクト指向と関数型プログラミングが深い部分で繋がっていることが感じられます。
それを言うと、何だって深い部分では繋がってます。
関数型プログラミングがオブジェクト指向の正当な後継であるというのはもはや極論ではないと思われます。
retemoさんの言いたいことは、おそらく、
- オブジェクト指向から関数型への移行には、それほど大きな障壁はないよ。
- 高水準の設計の技法・スキルは流用できるよ。
こんなことかな。そうなら異論はありません。ただ、それならそうと直截に言えばいいわけで、背景に無理筋な主張をあえて持ってくる必要があったんでしょうか? -- という疑問は残ります。
いずれにしても、retemoさんには経験と思いがあるのは確かでしょうから、事例、サンプルコード、図などを交えながら経験と思いをケレン味無く語れば、本来の目的である「オブジェクト指向と関数型プログラミングの関係」を伝えることが出来るのではないでしょうか。